

社会计算课的报告,虽然难度上不大,但挺花时间的
代码部分
- 1.对于第一部分影片票房的爬取,代码如下:
# coding=utf-8
import requests
import csv
import re
import os
from bs4 import BeautifulSoup
from aip import AipOcr
from PIL import Image
APP_ID = 'your APP_ID'
API_KEY = 'your API_KEY'
SECRET_KEY = 'your SECRET_KEY'
p_result = []
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en-CN;q=0.8,en-US;q=0.7,en;q=0.6",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "your Cookie",
"Host": "58921.com",
"If-Modified-Since": "Fri, 30 Oct 2020 06:00:00 GMT",
"Referer": "http://58921.com/alltime/2019",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
def hui_du(content):
with open("temp.png", "wb") as f:
f.write(content)
img = Image.open('temp.png')
Img = img.convert('L')
Img.save("temp.png")
with open("temp.png", "rb") as f:
content = f.read()
os.remove("temp.png")
return content
def baidu_ocr(img_src, last_box):
while True:
try:
img = requests.get(img_src, headers=headers)
except:
continue
else:
break
img = hui_du(img.content)
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
options = {}
options["language_type"] = "CHN_ENG"
options["detect_direction"] = "false"
options["detect_language"] = "false"
options["probability"] = "false"
limit = 0
pngjson = {}
pngstr = ""
while limit < 100 and pngstr == "":
limit += 1
pngstr = ""
pngjson = client.basicGeneral(img, options)
if 'words_result' in pngjson:
for x in pngjson['words_result']:
pngstr = pngstr + x['words']
if ord(pngstr[-2]) > 127:
pngstr = pngstr[:-1]
if "," in pngstr:
pngstr = pngstr.replace(",", ".")
boxoffice = eval(pngstr.replace('亿', "*10**8").replace('万', '*10**4'))
if isinstance(boxoffice, tuple):
print(boxoffice)
raise Exception
while boxoffice > eval(last_box):
boxoffice /= 10
return str(boxoffice)
if __name__ == '__main__':
last_box = "49.34*10**8"
for pages in range(27):
p_url = "http://58921.com/alltime/2019?page={}".format(pages)
p_response = requests.get(p_url, headers=headers)
p_response.encoding = 'utf-8'
p_soup = BeautifulSoup(p_response.text, 'html.parser')
p_list = p_soup.find_all("td")
j = 0
for i in range(len(p_list) // 8):
while True:
if "title" in str(p_list[j]) and "boxoffice" not in str(p_list[j]):
img_src = re.findall(r'src="(.*?)"', str(p_list[j+1]))[0]
img_word = baidu_ocr(img_src, last_box)
last_box = img_word
print("{} {:<30d} {}".format(p_list[j-2].text, int(float(img_word)), p_list[j].text))
p_result.append([p_list[j-2].text, p_list[j].text, str(int(float(img_word)))])
j += 1
break
j += 1
with open("movie_info.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(["pai_ming", "pian_ming", "box"])
f_csv.writerows(p_result)为了爬取2019年所有的影片票房,我选择对58921.com这个网站进行爬取。这个过程中比较难的一个点就是该网站上影片票房都是以图片的形式显示,因此不能直接爬下来。解决办法是将图片爬下来,然后使用百度的api进行ocr。但是百度的ocr不是非常靠谱,经常将图片中的小数点漏掉。我的解决方案是利用这个排行的特点,后一个影片的票房必定小于等于前一个影片的票房,而漏掉小数点只会使识别出来的票房更高,因此对其不断除以10直至不大于上一个票房为止。在ocr过程中的另一个点是原网站上显示票房的图片均为透明背景的png格式,因此可以使用pillow库将该图片先转化为灰度图,然后再进行ocr。
由于影片只有500多个,因此爬完后使用csv文件进行了存储。
- 2.对于影片评论的信息收集,代码如下:
# coding=gbk
import time
import random
import requests
import re
from bs4 import BeautifulSoup
from pymongo import MongoClient
def get_location(url, headers):
url = "https://www.douban.com/people{}".format(url)
headers = {
"Host": "www.douban.com",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate",
"Referer": r"https://api.weibo.com/oauth2/authorize?state=7his4sDMixE%2521douban-web%2521https%253A//www.douban.com/people/161270752/&redirect_uri=https%3A//accounts.douban.com/connect/sina_weibo/callbackaHR0cHM6Ly9hY2NvdW50cy5kb3ViYW4uY29tL3Bhc3Nwb3J0L2xvZ2luP3JlZGlyPWh0dHBzOi8vd3d3LmRvdWJhbi5jb20vcGVvcGxlLzE2MTI3MDc1Mi8%3D&response_type=code&client_id=1994016063&scope=&display=default",
"Connection": "close",
"Cookie": r'your Cookie',
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "max-age=0"
}
response = requests.get(url, headers=headers)
with open("try.html", "wb") as f:
f.write(response.content)
soup = BeautifulSoup(response.content.decode("utf-8"), 'html.parser')
loc_loc = soup.find_all('div')
result = "Unknown"
for i in loc_loc[::-1]:
if "user-info" in str(i):
loc = re.findall(r'<a href="(.*?)">(.*?)</a>', str(i))
try:
result = loc[0][1]
except IndexError:
result = "Unknown"
break
return result
movie_info = {
1: ["哪吒之魔童降世", "26794435"],
2: ["流浪地球", "26266893"],
3: ["复仇者联盟4:终局之战", "26100958"],
4: ["我和我的祖国", "32659890"],
5: ["中国机长", "30295905"],
6: ["疯狂的外星人", "25986662"],
7: ["飞驰人生", "30163509"],
8: ["烈火英雄", "30221757"],
9: ["少年的你", "30166972"],
10: ["速度与激情:特别行动", "27163278"]
}
client = MongoClient("localhost", 27017)
db = client.movie
for j in range(10):
collection = db[movie_info[j + 1][0]]
movie_id = movie_info[j + 1][1]
for i in range(0, 500, 20):
time.sleep(random.randint(50, 100) / 100)
url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&status=P&sort=new_score".format(movie_id, i)
headers = {
"Cookie": r'your Cookie',
"Host": "movie.douban.com",
"Referer": "https://movie.douban.com/subject/{}/comments?start={}&limit=20&status=P&sort=new_score".format(movie_id, ((i - 20) if i >= 20 else 0)),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content.decode("utf-8"), 'html.parser')
spans = soup.find_all('span')
peoples = re.findall(r'href="https://www.douban.com/people(.*?)">(.*?)</a>', str(spans))
count = 0
for i in range(len(spans)):
if 'class="short"' not in str(spans[i]):
pass
else:
comments = {}
comments["user"] = peoples[count][1]
comments["comment"] = spans[i].text
stars = re.findall(r'allstar(.*?) rating', str(spans[i - 2]))
comments["stars"] = str(int(stars[0]) // 10) if stars != [] else "-1"
comments["location"] = get_location(peoples[count][0], headers)
print(comments)
collection.insert_one(comments)
count += 1
print("{} end".format(movie_info[j + 1][0]))由于豆瓣的短评界面并未像长评一样使用ajax技术,因此可以直接爬取整个网页进行解析。每个界面20条评论,每条评论有给星数,影评,用户名,用户主页链接等信息,而用户主页中又有常居地的信息。爬取完成后,我使用了MongoDB数据库对信息进行了存储,但其实5000条数据完全没有比要用数据库存储。
- 3.情感分析部分的代码如下:
import requests
import json
import time
import pickle
from pymongo import MongoClient
ak = 'your API_KEY'
sk = 'your SECRET_KEY'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(ak, sk)
res = requests.post(host)
res = json.loads(res.text)
token = res["access_token"]
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={}'.format(token)
movie_info = [
"哪吒之魔童降世",
"流浪地球",
"复仇者联盟4:终局之战",
"我和我的祖国",
"中国机长",
"疯狂的外星人",
"飞驰人生",
"烈火英雄",
"少年的你",
"速度与激情:特别行动"
]
client = MongoClient("localhost", 27017)
db = client.movie
score = []
for j in movie_info:
collection = db[j]
senti_dict = {0: 0, 1: 0, 2: 0}
count = 0
for i in collection.find():
time.sleep(0.05)
data = {
'text': i["comment"]
}
data = json.dumps(data)
res = "error_msg"
while "error_msg" in res:
try:
res = requests.post(url, data=data).text
except:
res = "error_msg"
senti = eval(res)["items"][0]["sentiment"]
count += 1
print(count / 500, end="\r")
senti_dict[senti] += 1
print("\n" + j + ": " + str(senti_dict))
score.append(senti_dict)
with open("senti_dict.pkl", "wb") as f:
pickle.dump(score, f)由于时间上的紧迫,我直接使用了百度的api进行情感分析,尽管准确度稍有不足,但仍具有一定的参考性。分析完成后,将十个字典放入一个列表中,用pickle模块进行了序列化存储,这样可以方便可视化的时候进行直接读取。
- 4.影片票房部分的可视化的代码如下:
import matplotlib.pyplot as plt
import csv
plt.rcParams['font.sans-serif'] = ['SimHei']
movie_info = [
"哪吒之魔童降世",
"流浪地球",
"复仇者联盟4:终局之战",
"我和我的祖国",
"中国机长",
"疯狂的外星人",
"飞驰人生",
"烈火英雄",
"少年的你",
"速度与激情:特别行动"
]
boxes = []
highest_ten = {}
with open("movie_info.csv", "r") as f:
f_csv = csv.reader(f)
count = -1
for i in f_csv:
i = eval(str(i))
count += 1
if count == 0 or count % 2 == 1:
continue
elif count <= 20:
highest_ten[i[1]] = i[2]
boxes.append(int(i[2]))
fig, axj = plt.subplots(nrows=1, ncols=2, figsize=(15, 6), dpi=100)
axes = axj.flatten()
axes[0].bar(range(len(boxes)), boxes, color='blue')
axes[0].set_xlabel("票房排名")
axes[0].set_ylabel("票房")
axes[0].set_title("所有影片票房")
axes[1].bar(range(10), boxes[:10], color='red')
for a, b in zip(range(10), boxes[:10]):
axes[1].text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=8)
axes[1].set_xlabel("前十影片")
axes[1].set_ylabel("票房")
axes[1].set_title("票房排名前十的影片")
table = []
for i in range(10):
table.append([movie_info[i], boxes[i]])
axes[1].table(table, colLabels=["片名", "票房"], colWidths=[0.2]*2, loc="best")
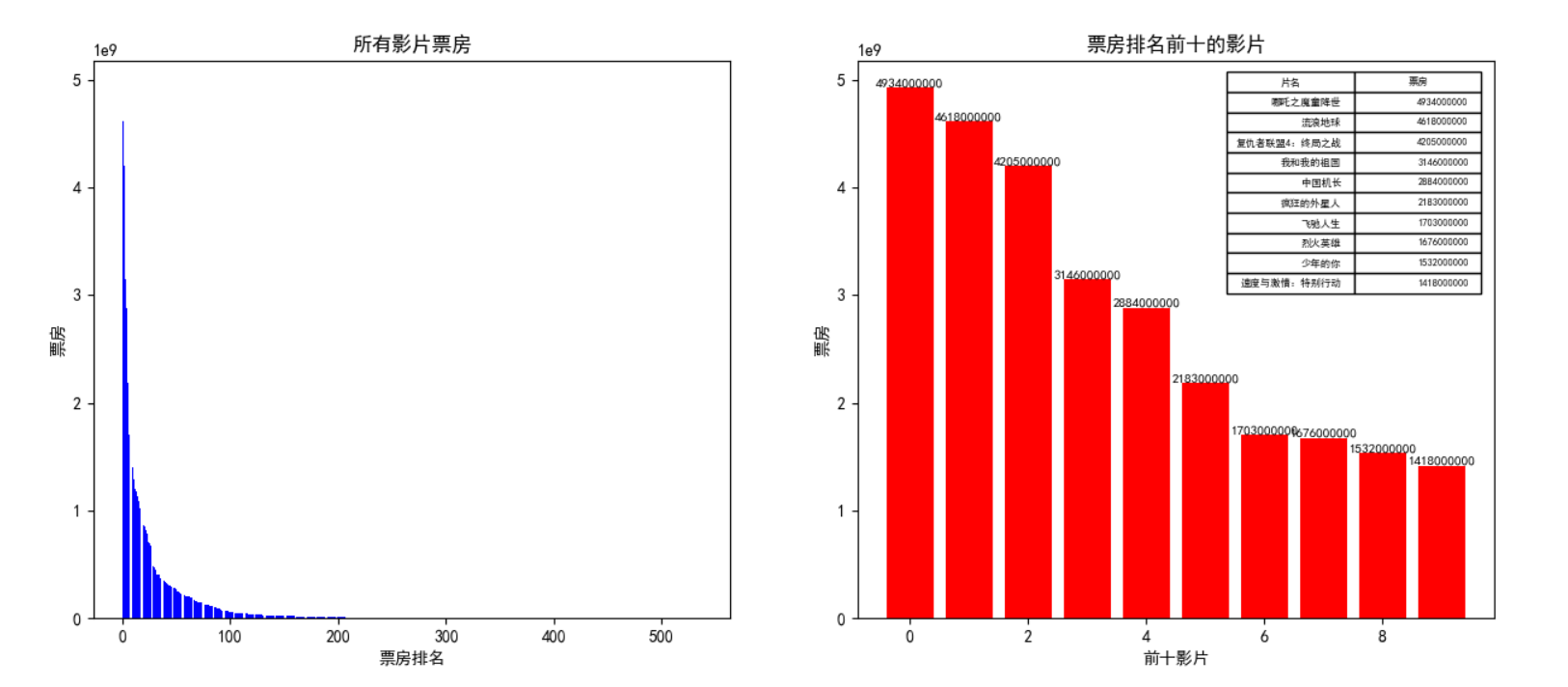
plt.show()该部分使用了matplotlib库进行可视化,结果以条形图的形式展现,可以直观地看出2019年影片票房的分布规律。
- 5.影评感情倾向部分的可视化的代码:
import pickle
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
with open("senti_dict.pkl", "rb") as f:
senti_dict = pickle.load(f)
movie_info = [
"哪吒之魔童降世",
"流浪地球",
"复仇者联盟4:终局之战",
"我和我的祖国",
"中国机长",
"疯狂的外星人",
"飞驰人生",
"烈火英雄",
"少年的你",
"速度与激情:特别行动"
]
fig, axj = plt.subplots(nrows=2, ncols=5, figsize=(15, 6), dpi=100)
axes = axj.flatten()
for i in range(10):
senti = senti_dict[i]
labels = ["消极", "中性", "积极"]
sizes = senti.values()
explode = (0, 0, 0)
axes[i].pie(
sizes,
explode=explode,
labels=labels,
autopct='%1.1f%%',
shadow=False,
startangle=90
)
axes[i].set_title(movie_info[i])
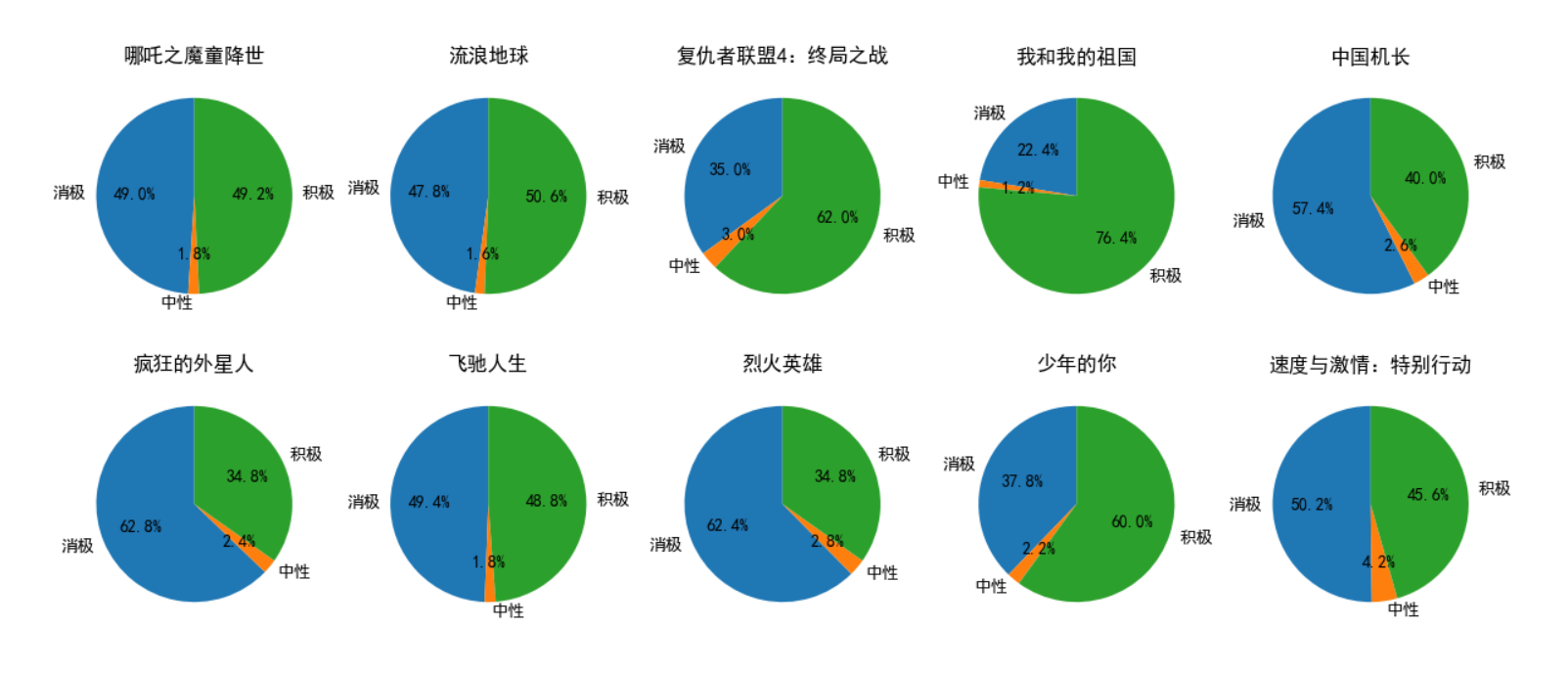
plt.show()使用了10个饼状图,可以直观地表现出各种感情所占的比例。
- 6.影评给星数的可视化的代码:
import matplotlib.pyplot as plt
from pymongo import MongoClient
plt.rcParams['font.sans-serif'] = ['SimHei']
client = MongoClient("localhost", 27017)
db = client.movie
movie_info = [
"哪吒之魔童降世",
"流浪地球",
"复仇者联盟4:终局之战",
"我和我的祖国",
"中国机长",
"疯狂的外星人",
"飞驰人生",
"烈火英雄",
"少年的你",
"速度与激情:特别行动"
]
fig, axj = plt.subplots(nrows=2, ncols=5, figsize=(15, 6), dpi=110)
axes = axj.flatten()
for j in movie_info:
collection = db[j]
stars = []
for i in collection.find():
if i["stars"] == "-1":
continue
else:
stars.append(int(i["stars"]))
axes[movie_info.index(j)].hist(
stars,
bins=5,
density=True,
histtype="bar",
stacked=True,
edgecolor="black"
)
axes[movie_info.index(j)].set_title(j)
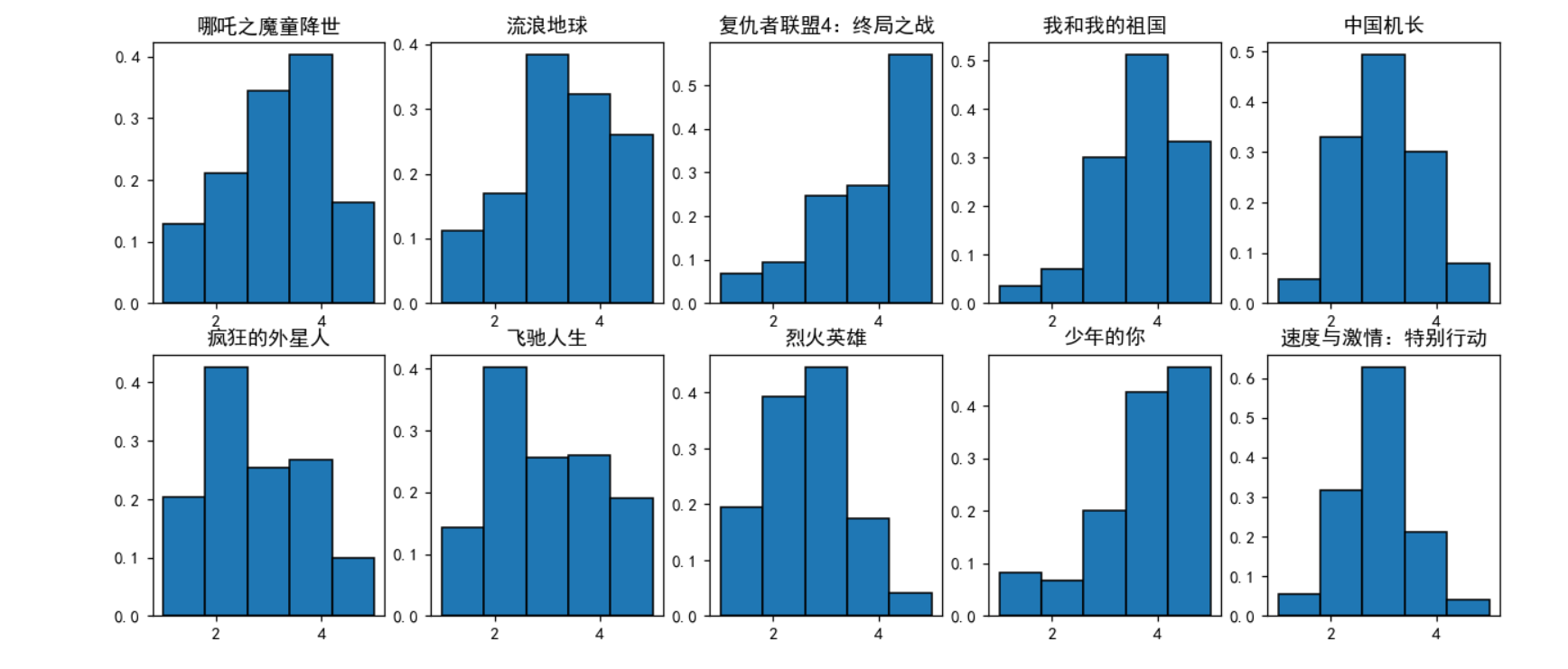
plt.show()使用直方图进行展示,可以清晰地看出各个给星数之间的数量差别,同时豆瓣自己的给星数展示也是使用的类似的图表。
- 7.影评人常居地的可视化的代码:
import matplotlib.pyplot as plt
from pymongo import MongoClient
plt.rcParams['font.sans-serif'] = ['SimHei']
client = MongoClient("localhost", 27017)
db = client.movie
movie_info = [
"哪吒之魔童降世",
"流浪地球",
"复仇者联盟4:终局之战",
"我和我的祖国",
"中国机长",
"疯狂的外星人",
"飞驰人生",
"烈火英雄",
"少年的你",
"速度与激情:特别行动"
]
def check_hanzi(stra: str):
english_exists = False
for i in stra:
if ord(i) <= 127:
english_exists = True
return english_exists
fig, axj = plt.subplots(nrows=2, ncols=5, figsize=(15, 6), dpi=110)
axes = axj.flatten()
for j in movie_info:
collection = db[j]
loc_dict = {}
for i in collection.find():
if i["location"] not in loc_dict:
loc_dict[i["location"]] = 1
else:
loc_dict[i["location"]] += 1
data = {}
for i in loc_dict:
if not check_hanzi(i) or i == "Unknown":
if loc_dict[i] > 13:
data[i] = loc_dict[i]
elif "国内其它地区" in data:
data["国内其它地区"] += 1
else:
data["国内其它地区"] = 1
else:
if "国外" in data:
data["国外"] += 1
else:
data["国外"] = 1
data = sorted(data.items(), key=lambda kv: (kv[1], kv[0]))
labels = []
sizes = []
for i in data:
labels.append(i[0])
sizes.append(i[1])
labels.reverse()
sizes.reverse()
axes[movie_info.index(j)].pie(
sizes,
labels=labels,
autopct='%1.1f%%',
shadow=False,
startangle=90
)
axes[movie_info.index(j)].set_title(j)
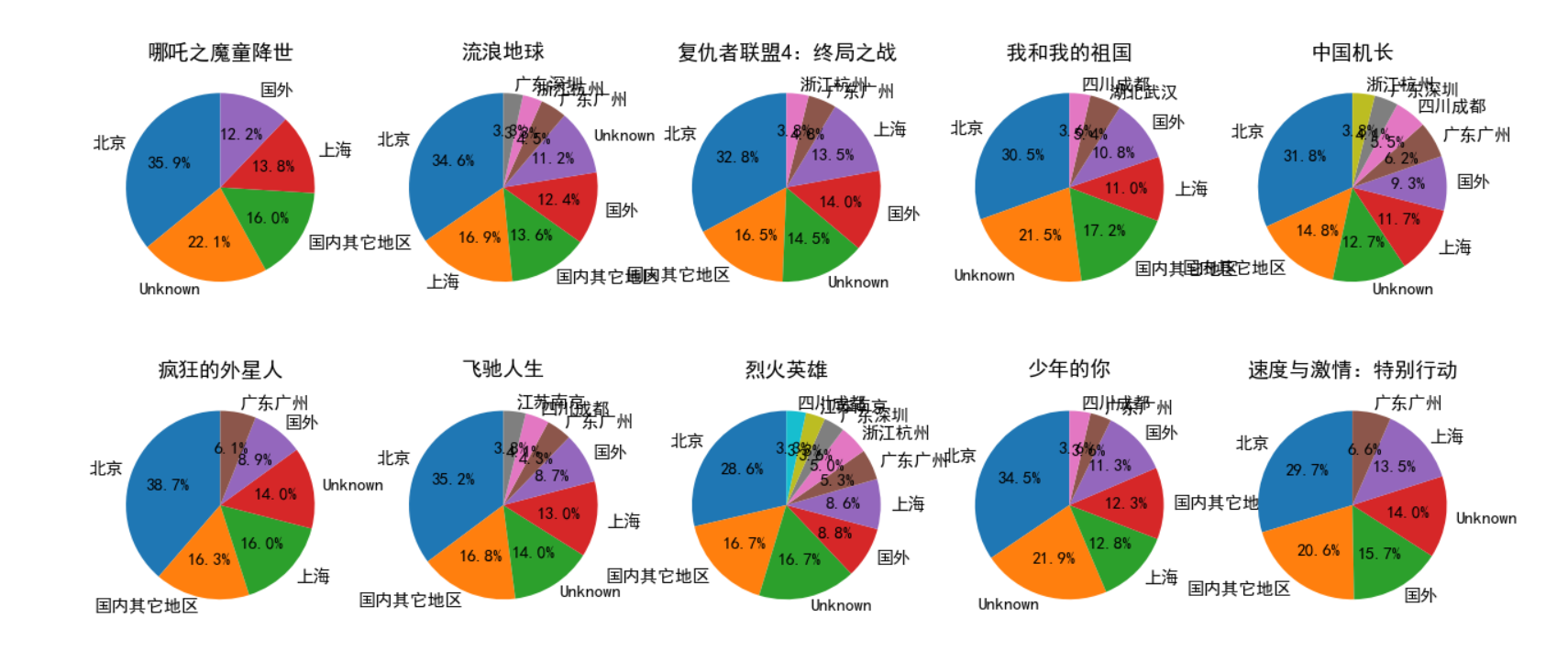
plt.show()该数据的处理部分较为复杂,因为常居地的可选项实在是太多,如果不做任何处理直接用饼状图表现出来,那么图中将出现大量的文字重叠在一起的情况。因此我参考示例中的处理,将国外的合并为一类,将国内的数量较少的地方合并为一类,最终得出了较为直观的饼状图。
成果
分析
流浪地球的给星数还没哪吒高就nm离谱,当初影院看的哪吒差点没把我尬晕,可能是已经过了哪吒的主要受众群体的年纪了吧
复联4的五星这么多是我没想到的,我印象中的豆瓣用户群体都挺鄙夷这种视觉特效轰炸的爆米花片的,可能是时代变了吧
常居地这个部分,人均北上广深+国外,只能说不出我所料
其它的,吐槽一下百度的情感分析的api,看个乐就好,真要分析还是用个什么snownpl自己训练吧